> Wolfe, Cameron R. 'Mixture-of-Experts (MoE): The Birth and Rise of Conditional Computation'. _Deep (Learning) Focus_, 18 Mar. 2024, [https://cameronrwolfe.substack.com/p/conditional-computation-the-birth](https://cameronrwolfe.substack.com/p/conditional-computation-the-birth).
# Mixture-of-Experts (MoE): The Birth and Rise of Conditional Computation
## Basic principles
- ==**Modern advancements in large language models (LLMs) are mostly a product of scaling laws.**== As we increase the size of the underlying model, we see a smooth increase in performance, assuming that the model is trained over a sufficiently large dataset.
- **==The fundamental idea behind a Mixture-of-Experts (MoE) is to decouple a model's parameter count from the amount of compute that it uses.==**
- MoE layers allow us to increase the size or capacity of a language model without a corresponding increase in compute.
- We replace certain layers of the model with multiple copies of the layer—called "experts"—that have their own parameters.
- Specifically, **we replace the feed-forward sub-layer of the decoder block with an MoE layer** (see the images below).
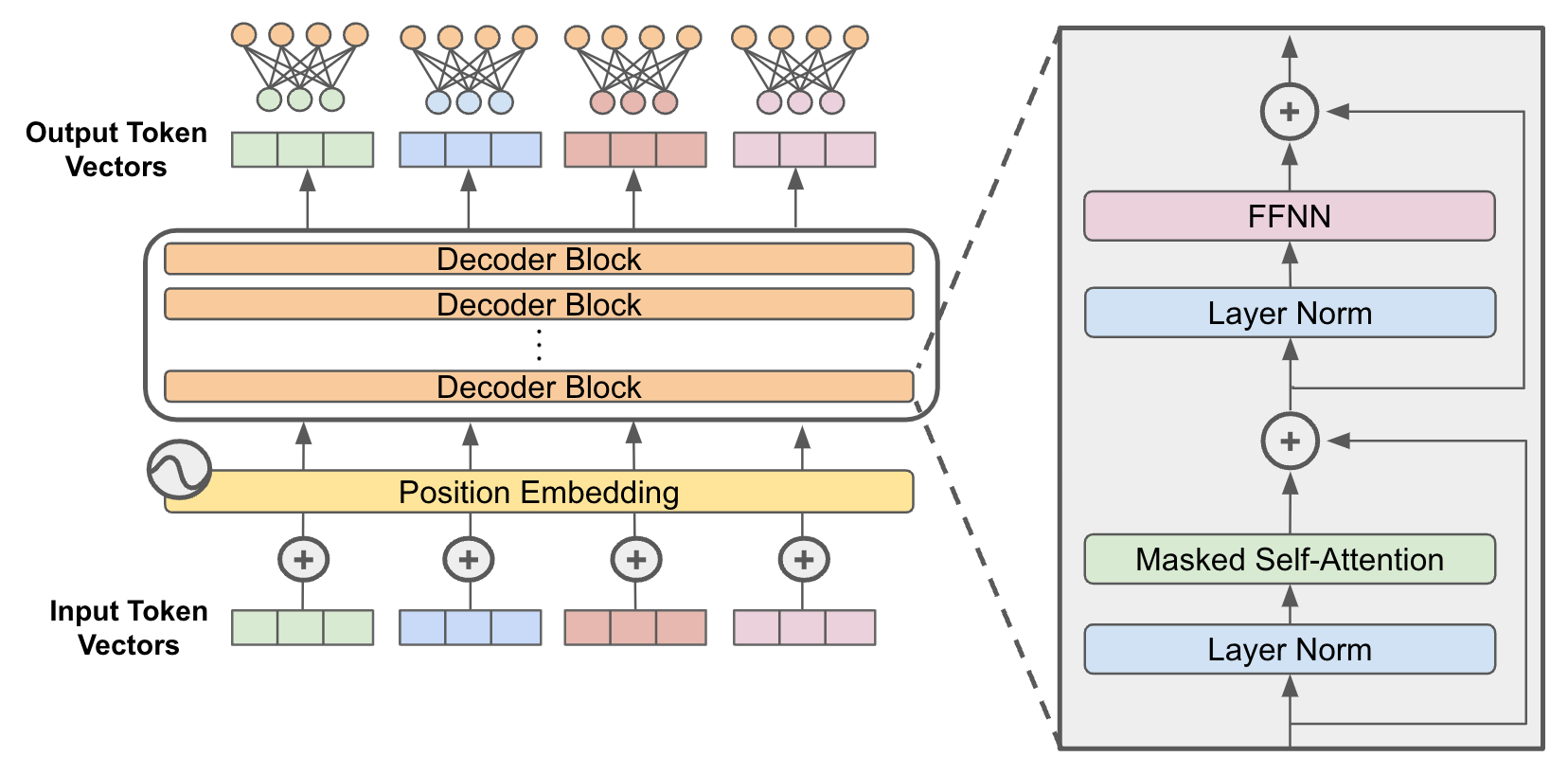
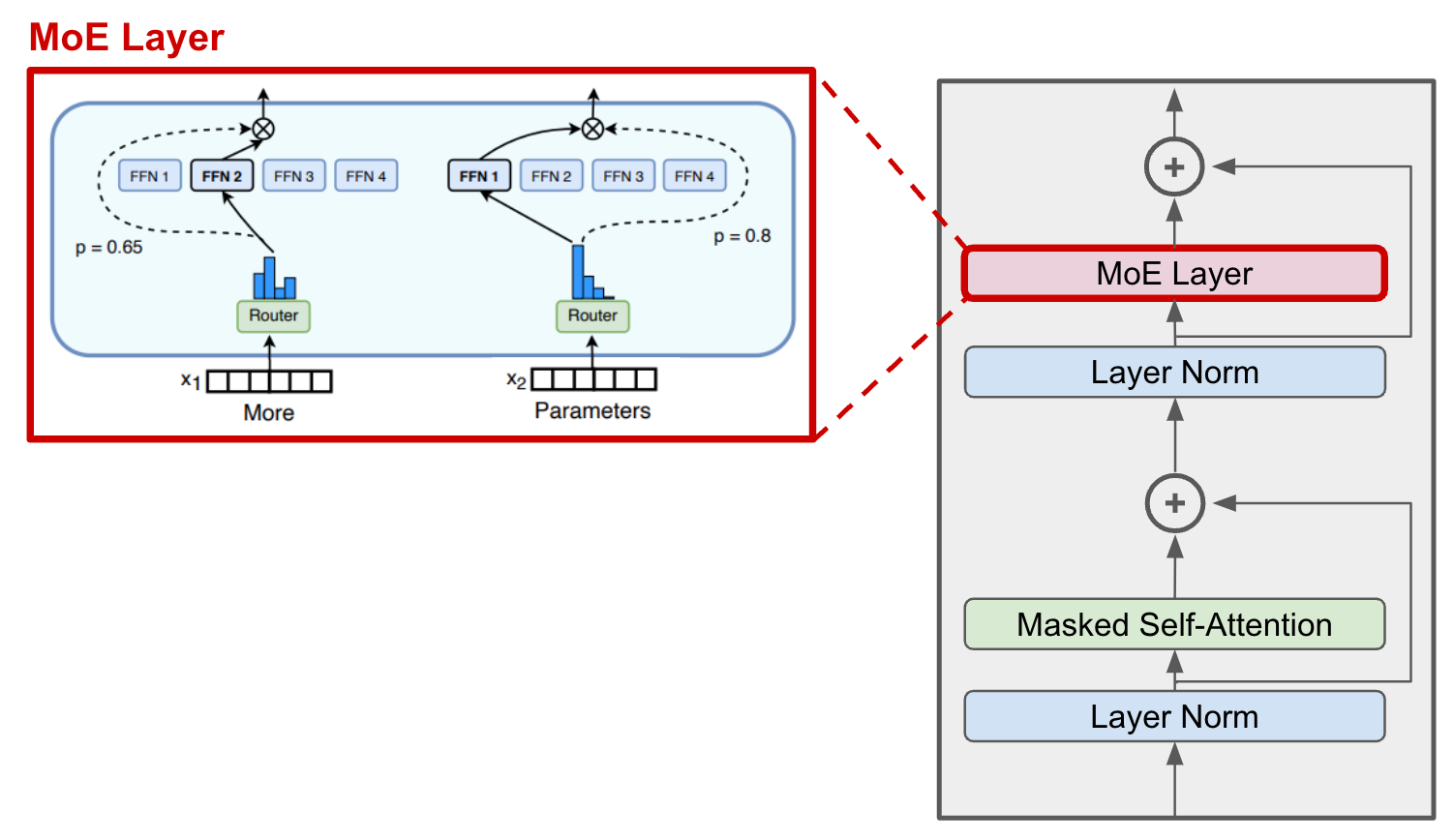
- We use a **gating mechanism to (sparsely) select the experts** used to process each input.
- Usually, we apply a linear transformation to the token vector, forming a vector of size $N$ (i.e., the number of experts).
- Then, we can apply a [softmax](https://en.wikipedia.org/wiki/Softmax_function) function to form a probability distribution over the set of experts for our token, and select the top-$k$ experts.
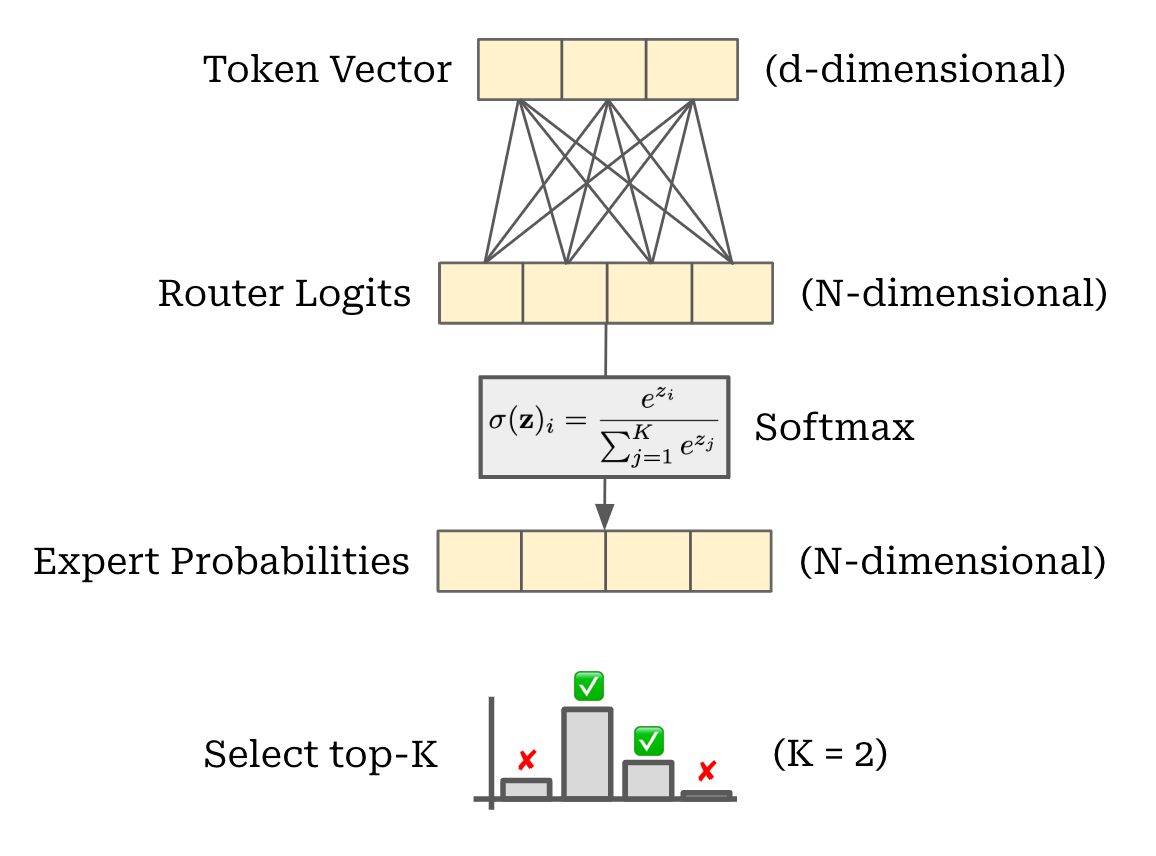
- We **compute the corresponding experts' output for each token and combine their results** to yield the output of the MoE layer.
## Discussions
- Given a sufficiently large pretraining dataset, **==MoE models tend to learn faster than a compute-matched dense model==**.
- However, MoE models also:
- **consume more memory** (i.e., we must store all experts in memory);
- **struggle with training stability**;
- **tend to overfit during finetuning** if there is not enough training data.
## 🔍 See also
- [[@wolfeMixtureExpertsMoELLMs2025|Technical Details for MoE Language Models]]